
机器学习和深度学习教程 – 李宏毅(笔记与个人理解)
本课程是学校课程之一,正好自己比较感兴趣然后就多学了一些(主要还是听不懂学校老师讲的……:joy: )
one:
第1讲:深度学习介绍:主要是基础概念的介绍,快速过一遍。
第2讲:为什么训练网络会失败:主要是将训练网络的一些细节,局部最小值,鞍点,自适应学习率,损失函数等。这一讲的选修的梯度下降必看,新的优化器可以先不看,如果有余力可以看,主要讲了对梯度下降的一些改进。
第3讲:图像作为输入:CNN网络,必看,非常重要
第4讲:序列作为输入:先看选修的RNN,再去看自注意力机制,不要搞错顺序。因为注意力太火了,所以RNN放在了选修,不过我认为还是要先看RNN模型基础,再去看自注意力机制,为下面额Transformer模型做准备。选修中的GNN网络,可以你自己的需求,入门阶段可以先跳过不看。
第5讲:序列到序列:主要讲了Transformer模型,必看,选修的指针网络可以先不看。
第6讲:生成模型:主要是对GAN理论的介绍。看你自己研究方向,如果是GAN方向的,可以细细看下,如果入门选手,直接跳过。
第7讲:自监督学习,必看,很火。主要看关于BERT介绍相关的视频,比如模型介绍,微调,预训练等。BERT的各种变体比如Spanbert等可以先不看,同理GPT有余力就看,没余力直接跳过,不影响。
第8讲:自编码,可以先不看,取决于你的自己研究方向。
第9,10,11,12,13,14,15讲,入门阶段可以先不看【取决于你的自己研究方向】,偏理论。入门之后,再来看。another one
如果是为了入门深度学习的朋友,重点看的章节我按照顺序罗列在下面:
1.机器学习基础概念:p2-p3-p7
2.Pytorch教程-不用看这里的视频,去看B站刘二大人的视频
3.反向传播基础知识:p8
4.案例讲解回归问题:p9
5.案例讲解分类问题: p10-p11
6.梯度下降算法: p18-p19【新的优化器讲解可以先不看】
7.卷积神经网络:p22;
8.RNN: p28-p29
9.自注意力机制: p26-p2710.Transformer: p32-p33
11.BERT: P47-p48-p50-p51
from 哔哩哔哩
day1
课程内容
- 什么是机器学习 找函数
- 关键技术(深度学习) 函数 – 类神经网络来表示 ;输入输出可以是 向量或者矩阵等
- 如何找到函数: supervised Learning 、 self supervised learning (pre train 又叫 Foundation Model 著名的例子有 Bert)、 Generative Adversarial Network、 Reforcement Learning
- 进阶内容 : Anomaly Detection 、 Explainable Al 、 Model Attack、 Domain Adaptation、NetWork Compression、 Life- Long learning 、 Meta Learning = learn to learn
Day2 introduction of Machine /deep Learning
Machine 是什么?
函数的不同类型
预测 分类
Structured learning 产生一个有结构的物件
一个例子 : Youtube Channel 的订阅量 找一个函数可以预测明天的观看次数
Step 1. y = w x1 +b Based on domain knowledge
Step 2. Define Loss From Training Data; Loss is a function of parameters L(b, w)
Step 3. Optimization w *, b * = arg min L ; Gradient Descent : 步长等于切线斜率(微分);然后还有一个n (ita)学习率来控制 w的变化长度 – > 通常自己设定hyperparameters
问题: 有可能陷入局部最优点; 可能的改进方法(self thinking)
1 取更好的初始点
2 改变学习率
3 找到所有的局部最优点(可以通过改变学习率进行跳出), 进行比较(例如找到十个不同的 局部最优点,然后进行min)
老师的伏笔: 高斯梯度 真正的痛点是什么?盲猜是 梯度消失 (wrong)
Gradient Descent
高斯梯度法的一般步骤:

how to improve linear model?
因为 linear model 过于简单 造成了一定的 model bias; 需要有更多未知参数的model
如图所示 , 红色的线可以由 常数+ 一系列蓝色的线来拟合

具体步骤如下:

0+1+2+3 = red line
发现:
所有的piecewise linear curves 都可以由blue line 组成
发现 more:
beyond piecewise linear 也可以
how to represent this function (blue line )?

用一个近似的曲线表示 sigmoid function
more thinking:
- how to find the first sigmoid ? 数学变换?–> 人口增长的背景下,概率论中的伯努利分布 f(x|p)=p^x^ (1-p)^1-x^
- and w and b here 和 前面的linear functon 是否有关?无关
实际可用的拟合函数(折线函数)

这里补充说明一点, 之前走了弯路, 以为这里的合成函数是一个分段函数, 后面的学习纠正过来, 这里就是单纯的 三个sigmoid 函数进行了 相加(有点多余, but who knows how could I say that )
NOw we have a new model which is more flexible


这里的w 表示特征,j表示特征的个数, 老师讲 如果是7天的话 j 就是1-7, 有一点点不明不白, 难道说之前的预测例子,是一个多特征的问题吗?
回忆, 好像确实和之前的linear model 有一点点不同, 一开始 取前一天,y = wx1 +b;后来取前七天的时候
注意这里的x 表示前j天的订阅次数, w 和b 是需要拟合的参数,也就是说这里至少需要拟合出7 组不同的w 一共有8 个参数(加上 b)。是根据前七天的订阅量, 预估第八天,相当于前七天是 不同的特征,预测第八天的特征,虽然老师这里的例子是实数值;换一个例子来表示可以这样理解: 选西瓜判断好坏瓜, 一开始只选择颜色(取值有 012 ),后来加上了 大小、响度,气味等不同的性状(取值为 0 1 2 ),然后预测瓜的取值(0 / 1 ); 从这个角度理解, 这个玩意儿相当于训练出 不同特征对于 结果影响的权重! nice
得出结论, 是的老师之前讲的例子确实相当于一个多特征的例子 √
言归正传, 那么这里老师讲得到一个 关于w 的参数矩阵, 和b,c 的参数向量,以及 最外面的b ;
那么接下来的问题就变成,优化 这些参数使得 L 最小 (nice!)


卡住了;
简单顺一下这个图是什么意思: x 表示前 1 2 3 天 的订阅量;
当 j 不变的时候, j = 1 ,表示,通过三个 blue line
去拟合 前一天的订阅量和y(第二天的订阅量)的关系;需要 3*3 +1 = 10 个参数; j = 2 / 3 的时候同上, ok pass ~
注意:w ${ij}$ 在这里表示每一个blue line 的斜率,w${ij}$表示每一个特征在每一次sigmoid 函数中所占的权重
more thinking :
这里的r1 ~r3 表示什么呢?根据式子来理解, 就只能是三种sigmoid 函数方法占预测结果的权重了
Day3
改写为向量和矩阵乘法的格式
接下来就分别把r 放到sigmoid方式里

简写以后 (向量化)

整个过程的向量表示: y = b + c^T^ a

一系列线性代数的表示方法(简洁)
Before we find the parameter (unknown) ,define some variable

Loss L(theta)


并不是用L 中的数据来训练参数,每一次更新参数的步骤叫做一次 epoch
Q:老师伏笔, 为什么这里要使用batch?
Day4

这里的batch Size 也变成了hyperparameter
一个hard Sigmoid 也等于两个relu的叠加
ActivationFunction

哪一种比较好?
神经网络训练的层数– 又一个 hyperparameter

a fancy name


为什么深? 而不更宽呢
Fully connect feedforward


这里可以用来推导矩阵的表示



相当于在隐藏层中,做了特征提取;输出层相当于一个多分类器

FAQ

Loss 的定义

这里的这个函数用的很奇怪,没见过,但是简单分析一下, 这个式子表示的还是y 和 y ‘ 的差距;but含奇怪的一点是 这里老师说 让这个参数越小越好 ……不应该是越大越好吗?因为有一个 负号
明白了 应该就是越小越好, 这里老师拿一个多分类的问题举例,所以这里用到了交叉熵的概念, 信息熵越小, 说明信息的混乱程度越小, 分类的 y1 –y10 越精确,之后的loss 见下一页ppt

啊 这里Loss 为啥上面的系数是 n 啊…… 哦对,我sb,n表示的是c 的序号,而不是幂次;
怎么回事, 怎么乱糟糟的, 这个c ^i^ 到底是什么时候出现的?本质上还是对交叉熵的概念不了解导致的
交叉熵(cross Entropy)
…… 这个概念暂时悬而未解吧
这里注意一下哈,
首先这个交叉熵的概念先放下, 就先用最常见的欧氏距离来表示这里的 y 和y ‘的差距,ok,第一个问题解决了;
第二点, 为什么这里需要用c ^i^ 以及它表示的是什么意思, 简单理解的话就是说, 每一个输入对应的一个输出和真实值的距离;因此有多少组输入就会有多少个c
第三点, c 对w的偏微分 一定是 ci 到 cn 同时进行 且等于 0 的,否则不能保证他们的和最小 (c i 到cn的和)
Day5 BackPropagation
什么是反向传播?
在train neru network 的时候 GradientDiscent的运作方式
Gradient Descent


c^n^ 表示 yn 和yn(head) 距离的function
chain Rule
正向传播:

找到规律,对谁的偏微分 ,就等于该输入
反向传播:



老师这里说 sigmoid ‘(z )是一个常数, 因为z在决定 前馈的 时候就已经决定好了;提问, 为什么?如何理解这个已经决定好了?
如果是按照常数的理解方法的话, z’ 又从何谈起呢?
…… 这个暂时学不进去了
Day6 BackPropagation(2)

用手推导了一遍具体数字的题目,对反向传播有了更深的理解: 本质上就是梯度下降法;没有丝毫新奇之处;只在于 在深度学习中, L(g(h(……w))),然后我们无法直接求出 L对w 的微分, 需要经过chain rule来进行,这个过程就是反向传播;
手推反向传播例题:
至于老师这里说的 sigmoid ‘(z )是一个常数;是因为 z 在前面的前馈中已经计算出来了,就等于输入值和w的线性相加,所以带入以后是一个常数;其实老师讲的很清楚了,是自己对过程不太清晰,把自己绕进去了。

两个case:
case1 . output layer
直接求即可
case2 . hiden layer(not output Layer)
我猜测还是和之前的一样,直到变成case1 为止


ok 我猜对了~嘿嘿

ok 小结一下,反向传播的意义在于减少运算~ 与其正向的求不出来算好几遍 对输出层的偏微分, 不如最开始就直接算 输出层的偏微分
但是扩大的倍率(图中的三角形)需要前一次的正向传播才能求出
Day7 Regression Case study (预测宝可梦的cp)
Regression 可以做什么? 股票预测 自动驾驶 推荐 预测宝可梦的cp(能力类似这样的属性把)
这里突然想到,是不是可以用洛克王国和赛尔号做事情哈哈
注意: 用下标来表示某一个完整的物体的某一个部分,例如:x 表示妙蛙种子;那么 xhp 就表示它的生命值,xcp 就表示我们要预测的战斗力等等
review 做机器学习的三个步骤:
- 找一个model(function set 关于函数的集合)
- 制定评价函数好坏的指标
- 找一个最好的function
Example:预测宝可梦
Step1 Model

注意这里的做法看似简单, 但是这种思想却是贯穿机器学习始末的:用简单的抽象的函数来表示我需要解决的问题


Step2 Goodness of function
抓取一部分的training Data 来训练我的参数
注意:这里用上标来表示一个完整的个体的编号; 在本课程中使用 y(head)$y\wedge$来表示正确的值
Loss Function : 一个函数的函数
input: a function ,output :how bad it is

因为f 是由w 和b 来决定的
Step 3 Best Function (Gradient Descent )
找到最好的function, 也就是使得 L 最小 
这里用线性代数的方法可以直接求 ,最速下降法(Gradient Descent)更有普遍性和计算机领域的意义

how can we do better ?
select another model




个人感觉这里用多项式进行复杂函数的逼近,有一点像泰勒展开(泰勒级数)不同的点在于,这里的w 是彼此无关的,然而泰勒级数的展开式和展开点相关性极强


从这里可以嗅到过拟合(Overfitting)的味道啦~
Let’s collect more data

what are the hidden factors ?

improve the model (consider the category )
Redesign the Model

这样的变形还是 linear model 吗?分段?


这里蓝色的部分就是我的feature ,本质上还是 linear model
Are there any other hidden factors?

使用了一个比较复杂的function ,发现过拟合了
两种方案:去掉不重要的因素feature
or Regularzation (正则化)

更加平滑; 减少 输入x
i对输出的影响; 红色的框框就是 Regularization的项
why we like the smooth ? (哎嘿~ 哈哈 :car: )
减少noises 的干扰(尤其是我们并不知道 noises 是什么的情况下, 如果知道的话 直接剪掉不就好了哈哈)

$\lambda$ 太小,过拟合, 太大 欠拟合
how smooth ? (如何选择 合适的$\lambda$) 这里老师简单跳过了,直接看图选
为什么不加b?
b 的大小和平滑程度无关,
Conclusion
- cp is determined b the before cp and the species
- Gradient Descent(我这里没有过多花时间,因为之前学过几遍了, 感兴趣的同学可以去看看吴恩达的Gradient Descent)
- Over fitting and Regularization (正则化) (这里加深了对正则化的理解,注意区分 正则化和 归一化这类预处理)

提问:好吧 不知道,感觉有高有低没有依据
Day 8 classification :Probabilistic Generative Model
今天上了一整天的课, 本来实在是更新不动了,但是看到《剑来》更新了,想一想这本书里面一直强调的成功的feature – 心性,嗯心性坚毅就好!主人公陈平安练拳一百万次,我才第八天而已,加油

主要任务
这里老师举了一堆案例,impressive – face reconization 因为之前接单刚搭了个项目 还赚了1k,哈哈


可以用来预测的属性(之后可以找到关键特征 extract features)

classification as Regression ?
这里还是有必要花一些时间的, 因为我一直以来的想法就是这个样子,也不明是非对错(学的一知半解的)大致思想就是下面

注意一下这里没有提到Loss function

就是说 我让一条直线, 橙色点输入进去小于0(sigmoid 之后接近-1) 蓝色点输进去 大于0(sigmoid后接近+1),最后可以找到绿色的线;loss 的话……我去我不会;
Q:这里的loss function 是什么?
sigmoid(wx +wx+b)-1 和 +1的平方;每一个点输进去哈



这些点是更加纯正的类,反而被error了,不合理 ,因为我们定义的模型是 越接近1 越是该类; 大于1 的点在我们这个模型里被认为是不应该存在的,超过了我的值域(ps:刚刚小憩了半个小时,真管用哇,本来想不通的东西困得不行还头疼,一下子想清楚啦哈哈)
另一个不合理:
当给类进行 -1 0 1 2 ……编码时候, 会认为 -1 class 和 0 class 离得比较近,实际上可能并没有这种距离关系
Ideal Alternatives (正确的做法)

这里把simoid去掉没有接近不接近1 的思想;g(x) 是自己学出来的一个function;
这里的loss 无法求梯度;
下面介绍贝叶斯

这里放了一个简单的推导:


利用x 的抽样分布来估计概率





对于 0的不存在的数据,假设它的(x的)分布符合某一个高斯分布,以此来估计概率

how to find the u and $\sigma$ 也就是找到概率最大的生成这79个点的高斯分布
MAximum Likelihood (极大似然)


这里应该是用了矩估计;当然了我们也可以进行求导的那种极大似然解法



bad Result

how to fix ?



xdm 绷不住了,学到这里的时候图书馆的朗读亭里有小姐姐唱歌了 爱的回归线 哈哈哈哈哈哈哈哈哈哈哈(那个朗读亭隔音不好,很多同学以为那个地方可以隔音),唱的还挺好听的;
平均数还和原来的算法一样
这里有一点不明白 为什么这样就可以表示它的方差?(加权平均) 为啥不是直接把140个点求一个方差呢?
more Result

Three Steps 三板斧

other thinking

Some math一些数学的推导:


posterior probability 后验概率:考虑了一系列随机观测数据的条件概率。对于一个随机变量来说,量化其不确定性非常重要。其中一个实现方法便是提供其后验概率的置信区间。



从这个式子可以看出,共用$\Sigma$ 的时候,为什么 boundary 会是一个直线


老师讲的真牛x,这里直接串起来了,后面紧接着讲logistic Regression
Day9 Logistic Regression(内涵,熵和交叉熵的详解)
中间打了一天的gta5,图书馆闭馆正好+npy 不舒服那天+天气不好,哈哈哈哈哈总之各种理由吧,导致昨天没弄起来,今天补更!

这里重点注意一下, 这个 output值是概率哈,也就是说式子整体表示的含义是 x 属于c1的概率是多大

这个老师真的是讲到我的心坎子里区了,这个logistic Redression 和linear Regression 长得真的好像啊,我自己正有疑惑怎么区分,then……

不知道你们看到这里在想什么哈,反正我的第一个反应就是,woc这logisticRegression不是长得和之前的全连接神经网络的神经元一毛一样吗?甚至还是加上了激活函数,sigmoid的

这里就只有概率论的知识哈,这里为什么是1-f(x^3^ )? 我自己想的话是因为这个回归只回归 C1 的情况,或者说,对于不同的类要做一个处理后,再进行回归


比较巧妙的使用 01 关系来表示了不同的类的回归情况(注意这里不是做分类任务哈, 不要看见class1 啥的就说是分类任务, 敲黑板,看我们的title 是什么?!)

cross Entropy
这里又出现了,cross Entropy的概念,逃不掉了……那就捡起来补一补:
**熵和交叉熵 **:
从信息传递的角度来看:
信息论中熵的概念首次被香农提出,目的是寻找一种高效/无损地编码信息的方法:以编码后数据的平均长度来衡量高效性,平均长度越小越高效;同时还需满足“无损”的条件,即编码后不能有原始信息的丢失。这样,香农提出了熵的定义:无损编码事件信息的最小平均编码长度。
so, how we get this coding length ?( more deeper :何来的最小,又何来的平均呢?)
eg: 假设我考研的地方有四种可能,然后我要把这个秘密的消息==传递==给我的亲人
编码方式/事件 北京 60% 四川 20% 天津 15% 其他 5% 平均编码长度 方式1 0 1 10 11 1 * 0.6+1 * 0.2+ 2 * 0.15 +2* 0.05 = 1.2 方式2 0 1 111 110 …… 方式3 11 10 0 1 2 * 0.6+2 * 0.2+ 1 * 0.15 +1* 0.05 = 1.75 我们通过计算可以看到,方式1 的平均编码长度是最小的;(这里又想到学c的时候学到的 哈夫曼树,细节上还是有很大不同,由于它用到了树的结构,并不能完全灵活的得到最小编码举例: asdfgh 六个字母,编码出来的最长编码有1001 等,如果直接进行编码 则0 1 10 11 100 101 110,最长仅有3);那么最小编码长度就是,大于N(事件情况)的2的最小次方 ,然后按照出现概率递减依次递增编码;那么计算平均最小长度,(ps:我是真nb,这个小的推导过程我先自己想的,网上一验证发现还真的对了我去)也就是熵的公式为:
熵的直观解释:
那么熵的那些描述和解释(混乱程度,不确定性,惊奇程度,不可预测性,信息量等)代表了什么呢?
如果熵比较大(即平均编码长度较长),意味着这一信息有较多的可能状态,相应的每个状态的可能性比较低;因此每当来了一个新的信息,我们很难对其作出准确预测,即有着比较大的混乱程度/不确定性/不可预测性。
并且当一个罕见的信息到达时,比一个常见的信息有着更多的信息量,因为它排除了别的很多的可能性,告诉了我们一个确切的信息。在天气的例子中,Rainy发生的概率为12.5%,当接收到该信息时,我们减少了87.5%的不确定性(Fine,Cloudy,Snow);如果接收到Fine(50%)的消息,我们只减少了50%的不确定性。
交叉熵
卧槽我一下子就懂了,我tmd 简直就是个天才哈哈
这样想:熵的定义 是该分布下的最小长度;上面那个公式有两个部分我们现在确定不了,p(x)的分布和 需要编码的长度;其实我们做一个预测的时候是啥也不知道的,但是这样不就没法算了嘛,我们不妨假设P(x)是我们知道的,也就是真实的值,那么剩下的编码长度就是观测值咯log
2(Q(x)),那么由于Entropy的定义, 是p(x)分布下的最小长度的编码,就不可能出现比这个编码更小的数,所以交叉熵越小,说明我们越接近p(x)分布下的最小长度的编码。(也就解释了,机器学习分类算法中,我们总是最小化交叉熵的之前的疑问)定义这玩意儿的人也是个天才md




感觉这里老师讲错一个东西, 当这两个函数一模一样的时候 得到的不应该是0 吧


之前我就 是这么做的笑死,直接被当反面教材




这里有一点小疑问,为什么不是 学习率×这里的w的变化率 ?

NB chatgpt 上大分,这里就是✖ 那个求和符号管的是后面,这个应该就是见的比较少,所以才有疑问



Discriminative VS Generative





< 0.5
Generative 做了一些假设,脑补了一些数据;这个例子朴素贝叶斯 认为 没有产生11 是因为 sampling的不够多

Multi-class classification



概率或者信息论的角度可以解释

这样编码为什么就没有 关于某几个类之间更近的问题了?
这是一个独热编码(one-hot encoding)的例子。例如,如果有三个类别,那么第一个类别表示为100,第二个类别表示为0,1,0,第三个类别表示为0,0,1。这种编码方式确保了每个类别之间的“距离”是相同的,因为它们在高维空间中是正交的。
Limitation of Logistic Regression






引出 类神经网络 deepLearning
Day 10 Genaral GUidance



training Loss 不够的case







Loss on Testing data
over fitting


为什么over fitting 留到下下周哦~~ 期待
solve



CNN卷积神经网络
Bias-Conplexiy Trade off


cross Validation

how to split?
N-fold Cross Validation

mismatch

这节课总体听下来比较轻松,二倍速一路刷过去了,看看明天的课还会不会这么轻松吧哈哈,期待,今天实操了一下线性回归的东西 还不错有意思~
Day11 when gradient is small……



怎么知道是局部小 还是鞍点?
using Math



这里巧妙的说明了hessan矩阵可以决定一个二次函数的凹凸性 也就是$\theta$ 是min 还是max,最后那个有些有些 哈 是一个saddle;
然后这里只要看hessan矩阵是不是正定的就好(详见 线性代数)
example – using Hessan



奇怪这里为什么不是主对角线呀,难道两个都一样嘛 晕死,得复习线代了
Dont afraid of saddle point(鞍点)

征向量 u 和对应的特征值 λ定义为满足下列关系的向量和标量:Hu=λu
在梯度下降算法中,我们希望选择使得 L*(*θ) 减小的 θ 方向。如果 λ<0,则向 u 的方向移动参数 θ 会减小损失函数 L(θ)。
换句话说,如果我们发现了一个负特征值λ 和相应的特征向量u,我们可以通过沿着 u 的方向更新 θ 来降低损失函数的值。这就是图中所说的“Decrease L”的含义。


local minima VS saddle Point




引入高维空间的观点,解决local minima的问题:我们很少遇到local minima;

Day12 Tips for training :Batch and Momentum
why we use batch?
前面有讲到这里, 前倾回归
<img src="https://markdown-pictures-jhx.oss-cn-beijing.aliyuncs.com/picgo/image-20240411193721913.png" alt="image-20240411193721913" style="zoom:33%;" />

这里大家记得问自己一个问题:一个epoch 更新多少个参数?nums(batch)* parameters
例如,如果你有100个batch,那么在完成一个epoch后,每个参数会被更新100次。
shuffle :有可能batch结束后,就会重新分一次batch
small vs big
这里举了两个极端的例子,也是我们常见的学习方法:取极限看效果


未考虑平行运算(并行 –gpu)







over fitting: 比较train 和test


| Aspect | Small Batch Size(100个样本) | Large Batch Size(10000个样本) |
|---|---|---|
| Speed for one update (no parallel) | Faster | Slower |
| Speed for one update (with parallel) | Same | Same (not too large) |
| Time for one epoch | Slower | Faster |
| Gradient | Noisy | Stable |
| Optimization | Better | Worse |
| Generalization | Better | Worse |
batch is a hyperparameter……

Momentum
惯性



知道学到这里想到什么嘛……粒子群算法的公式不知道你们有没有了解,看下面那个w*v
i有没有感觉这种思想还挺常见的,用来做局部最小值的优化的



concluding:

Day13 Error surface is rugged……
Tips for training :Adaptive Learning Rate
critical point is not the difficult





Root mean Square –used in Adagrad

这里为啥是前面的g的和而不是直接只除以当前呢?
这种方法的目的是防止学习率在训练过程中快速衰减。如果只用当前的梯度值来更新学习率,那么任何较大的梯度值都可能会导致很大的学习率变化,这可能会使得学习过程不稳定。通过使用所有过去梯度的平方的平均值,我们可以使学习率的变化更加平滑,因为这个值不会因为个别极端的梯度值而发生剧烈波动。
以及这个式子和之前讲的那个正则化是不是一样的呢?
啊!!!woc 我发现这两个是差不多的思想啊,你把上面那个正则化的东西用Gradient做出来
gi= 2xw+$\sum$ 2w…… 额……好吧完全不一样,但是我又不知道这个会不会对于我的……废了,乱了;稳一稳哈
- 这里为什么不是让这个梯度直接等于0 呢?– 或许是因为有的loss function 我们无法直接求出来梯度等于0 的w?哦哦 那我就知道了md 吓死,差点以为自己的machine Learning route ending了




RMSProp
因为上一个方法只能解决 不同的$\theta$ 时候的学习率,但是由图我们可以知道有时候同一个参数我们也希望起有变化率的不同取值

我怎么没看出来这种思想啊





解决井喷问题

在bert里面需要用到


SUmmary of OPtimization


下节预告:

Day 14 Classfication (short version)






二分类的时候 用sigmoid 那不就是 logistic 回归嘛(softmax 的二分类等价)
Loss


哦 今天刚学的 ,KL散度 ,看来cross-entropy 和KL散度是等价的咯~ 我感觉我的直觉没错

这里MSE离得很远的时候会梯度消失,致使训练变得困难;
tell me WHY?
非线性激活函数:当使用非线性激活函数(如Sigmoid或Tanh)时,在输入值非常大或非常小的情况下,这些激活函数的梯度会接近于零。因此,如果在MSE损失函数的情况下,预测值与目标值之间的差异很大,经过激活函数的反向传播会产生非常小的梯度。
但是Cross Entropy 两个差距很大的时候整体乘积并不会无限大 — 因为本质上描述的是两个概率分布的差异
Day 15 重温宝可梦分类器 – 浅谈机器学习基本原理
REview 见我之前的笔记即可~

More parameters , easier to overfit ,why ?



Step 1 a function (Based on domain knowedge)

线条的复杂程度?
Edge Detction




Step 2 Loss


这里注意一下哈,这个corss-entropy 不能直接微分, 那就直接爆搜
step 3 Train find the best








What is the probability of sampling bad Dtrain ?
万能近似!




不等式变号即可





这里应该用数理统计那块儿东西可以做



霍夫丁不等式(Hoeffding’s Inequality)是概率论中的一个重要结果,它提供了一种评估独立随机变量之和与其期望值偏差的概率的方法。具体地,如果有一组独立的随机变量,每个随机变量的取值范围都是有限的,那么这些随机变量之和的实际观察值与其期望值的偏差超过某个界限的概率是非常小的。
霍夫丁不等式的数学表达式是这样的:
这两个不等式给出了随机变量之和大于或小于其期望值一定范围的概率上限。
根据霍夫丁不等式,如果在足够大的训练集上,算法的误差已经非常小,那么我们有很强的信心认为,在未知的测试集上,算法的误差也会控制在一个很小的范围内
tmd 不推了暂时,推的我脑袋疼,缓一缓哈 缓一缓
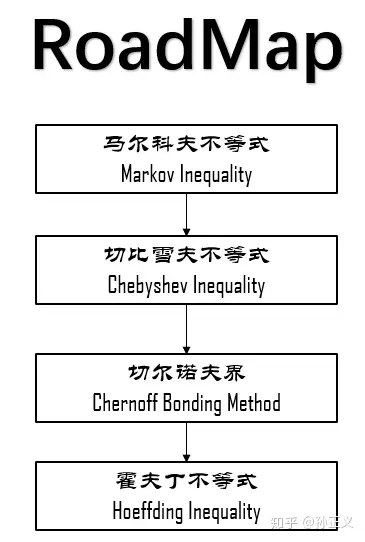
具体参考





Example



这个问题真的提的很好啊! 如果是连续的怎么办呢? 连续的时候 用VC-dimention 来算模型的 复杂程度


怎么办?
鱼与熊掌兼得 – Deep Learning
Day 16 deep Learning – 鱼与熊掌兼得

Review 见前面的笔记





这里说dl 会提供一个足够大的模型, 来使得Dall loss 足够小,但是从这里没有看出来deepLearning 更好呀,这不是还是需要一个big training data 嘛
Fat or Tall?


Why?

同样的function 参数较少 – 以为着较少的over fitting and less training data








Day 17Convolutional Neyral Network (CNN)
卷积神经网络一般都用在image 上面比较多一些,所以课程的例子大多数也都是image
Image Classification
the same size

how about for pc?

这里对于tensor 张量这个概念,我还是比较奇怪,在我认为一个矩阵也可以表示三维的空间;为什么引入tensor这个概念;
听完那个课程我悟了,tensor作为多维数组来说,更具有高维空间的特性;就拿上面的图片举例子,extremely case 我们取一维向量来表示(铺开),这样就会丢失一些空间的信息,例如绿色的格子和蓝色的某个格子其实是垂直的,仅仅相差一个垂直距离,但是展开为一根棍就很难找到这种关联
向量中某一个格子的数值表示该种颜色的强度

好了我猜你紧接着就要说,啊啊啊这个什么weight 太大了,更新一次太麻烦啦巴拉巴拉的
Do we need “fully connected” in image processing ?
so we need some observations
Obervation1

so not whole image ,but some patterns
Simplification 1





Typical Setting

Obervation 2

Simplification 2 sharing parameters

Typical

有了两种简化的方式了,我们来总结一下我们学到了什么

CNN 的model 的bias比较大
Fully connected Layer jack of all trades master of none
Another Story







这张ppt好好理解一下, 理解不了的话我给你讲讲:
首先按照Convolution 分为上下两个 part 哈,上面那个是由64个fitter (高度/厚度 =1, 因为原始图像的channel =1 是黑白图像,这里我们考虑typical的情况) 分别对原image做卷积得到的;每一个高度可以作为一个feature Map;ok ,然后我们知道 RGB 其实也是一个图像的三个channel 三个 feature Map;那么我们自然而然的认为这个厚度为64的feature map 叠起来的厚吐司 也是一个64channel 的图像;迭代为原始图像,那么下一次进行卷积的时候我们就需要64个厚度为64的fitter,也就是下面的两个64 的不同含义~ ok,打完收工
一个问题,如果fitter 一直等于 3*3 会不会严重丢失全局信息?为什么?
- 我认为和stride有关,一直有重叠
- 更直接的解释 从 3 * 3 到 5 * 5

殊途同归

boy 聪明的,比较颜色就好~ 要学会适度自学哦


Observation 3

Simpification 3(Pooling)


subSampling 会丢失一定的信息,随着 计算机上升,下采样逐渐式微
The whole CNN……

Flatten 拉直
Application– 阿尔法狗

so why CNN?

当成一个图片,然后48个channel 表示该点处的48种情况



more thinking :
CNN 好像没有办法处理影响放大缩小,或者反转的情况;so we need data augmentation ;
Spatial Transformer Layer
Day 18 Spatial Transformer Layer(数字图像处理)
上回书说道:因为单纯的cNN无法做到scaling(放大)and rotation(转),所以我们引入;
实战中也许我们可以做到 是因为 我们的training data 中包含了对data 的augmentation;
有一些 translation的性质,是因为 max pooling

这张ppt好好理解,我感觉它说明了spatial Transformen的 本质
- 专门训练一个layer 对图像进行旋转缩放
- 由于本质上还是一个神经网络结构,所以可以和CNN join it to learn 就是一起训练嘛(End to End)
- 不仅可以对input image 做变换(transform),也可以对CNN 的feature map进行
ok 以上说的三点就是它的特性了,应该没有哪一个是不懂的吧~
至于 why 1 ,下文来介绍它的工作原理

这张图我自己又加了一些笔记, 这里说的 是全连接的工作原理; hope you learned
我们可以用全连接来做transform ,例如


好了,基本学会了,就是数字图像处理学的那点东西,就是乘一个变换矩阵就好了



好了,没什么了不起,就是用神经网络 训练出三个变换矩阵
举例:


max pooling(IOU 连接网络?) 如何用Gradient Descent 解呢?

这里老师判断的角度应该是 对于参数的 $\Delta$ w 会有一个 $\Delta$y 与其对应,但是这个case 里面$\Delta$y = 0; 梯度为0 消失~
这样也能理解为什么老师认为max pooling 可以用来解,因为随着参数的变化,max的值一定会有变化,则可以进行梯度;即使max ()本身是不可微的
Interpolation – 双线性插值

详情请参照 《数字图像处理》


固定了两个参数, 有点focus 的味道, 因为无法做旋转嘛智能做缩放
Day 19 Recurrent Neural Network (RNN 1)
md 发现我最近需要恶补一下vue的技术……服了(因为有两个项目要交单子了)
好吧导致我停更新两天的DL,我去如坐针毡啊!今天补上
- Slot Filling




将词语用向量的形式来表示;
提问:中文如何处理?


检测不到 前面的那个词语;
提问: 为什么不把整句话输入进去?
这样应该可以,但是如果是一个很长的段落呢?把整篇文章进行encode 是不合理的
needs memory
(Elman ) Recurrent Neural Network(RNN)




把这个流程走通!!!! 一定记得走通哈
Then we have a model which can store the order
考量时间顺序的那个kaggle
提问: 如果我们的nlp呢? 有一些倒装句应该如何处理使得其语义相同?



Elman & Jordan Network

这两个图如果看不懂的话 说明没有弄懂上面的 流程
Bidirectional RNN

检测范围较广,不仅上文, 还有下文;用来解决倒装句比较不错哈
Long short -term Memory (LSTM)


正常的输入和三个控制门讯号的输入
和RNN比较起来, 强化了对整体序列的记忆;并且可以 认为的通过lable 训练出需要记忆的重点序列

内部逻辑图!需要重点掌握哦!
- “h” 通常表示 LSTM(长短期记忆网络)的输出门中使用的激活函数。在 LSTM 单元中,输出门决定了有多少当前单元状态要输出到下一个时间步骤。这个 “h” 函数通常是一个 sigmoid 函数。
- “g” 表示在计算新的单元状态时使用的激活函数。这个函数通常是一个能够输出较宽范围的函数,例如双曲正切函数(tanh),其输出范围是 -1 到 1。这允许网络调整其内部状态,通过结合之前的状态和当前的输入。
这里我也不明白为什么要弄两个激活函数? 是普通的network 也是两次激活函数吗?
需要注意的一点是 forget gate 的取值 ,应该交 remember gate 会好一些


来吧 ,整个LSTM 最重要的ppt ,走动这个ppt 你就懂了LSTM的工作原理

如何理解LSTM和普通network的关系?

图中的+ 代表我的输入; 小圈圈代表激活函数; 划线代表不同的weight





太扯淡了!
this is quite standard now

Day 20 RNN 2 实际使用和其他应用
在实际的学习(training)过程中是如何工作的?
step 1 Loss

step 2 training

Graindent Descent
反向传播的进阶版 – BPTT


CLIpping 设置阈值~ 笑死昨天刚看完关伟说的有这玩意的就不是好东西

Why?出现了梯度steep or flat

这里为什么不可以用Adagrad(RMS)或者 Adam(RMSPROP + momentum)?


LSTM 可以解决梯度平坦的问题,但是不能解决steep,所以可以放心的将学习率设置的小一点;原理如下,凑乎看


根据上面的思想,那么我可能需要保证我的forget gate 大多数情况下是开启的 (保留记忆)
Grated Recurrent Unit (GRU)Simpler than LSTM
联动forget 和 input gate 2选1
只有清除记忆新的Input 才能被放入

More Application
这一部分整体感觉 好难,应该是因为嵌入了不少论文的原因,耗费脑子

一到多


多到多(outputer is shorter) – 语音辨识 (贝叶斯)



有一个好的穷举算法

多到多(no LImitation)
翻译




????没看懂这里,这个断是在哪里加入呢;假设在训练过程中添加了这个symbol

不仅仅 是sequence

使用LSTM做句法解析时,如果输入句子有语法错误,如缺少括号,这种错误通常不会直接影响LSTM模型的解析过程,因为LSTM并不是基于规则的解析器,而是基于学习的模型。它通过从大量的标注数据中学习语言的统计特征,来预测句子的结构

什么是词袋模型?
词袋模型(Bag of Words,简称BOW)是一种常见的文本表示方法,用于自然语言处理和信息检索领域。这种模型忽略了文本中词语的顺序和语法、句法元素,仅仅将文本(如一句话或一篇文章)转换为一个集合,其中包括了词汇表中每个词的出现次数。可以将其想象为一个词的“袋子”,只记录词的存在与频率,而不考虑其出现的顺序。
词袋模型的步骤通常包括:
- 分词:将文本分割成词语或标记。
- 构建词汇表:从所有文本数据中提取出不同的词语,构成一个词汇表。
- 计数:对于每一个文本,计算词汇表中的词语在该文本中出现的次数。
可以把一个document 变成一个 vector

这个听不懂,让gpt试试
《A Hierarchical Neural Autoencoder for Paragraphs and Documents》探讨了如何利用长短期记忆网络(LSTM)自编码器生成长文本。核心思想是通过建立层级LSTM模型,将文本(如段落或文档)编码成向量,然后再解码重构原文本。这种层级模型能在不同层次上捕捉文本的组合性,如单词间、句子间的关系,从而在重构时保持文本的语义、句法和篇章的连贯性。实验表明,这种模型能有效重构输入文档,并且在维持原文结构顺序方面表现良好。
层级LSTM(Hierarchical LSTM)模型通过构建不同层级的LSTM结构来处理文本数据,其中每个层级对应文本的不同组成部分(如词、句子和段落)。在编码阶段,每个词首先通过词级LSTM(LSTM_word_encode)转换为词向量,这些词向量再通过句子级LSTM(LSTM_sentence_encode)组合成句子表示。同理,所有句子表示再通过一个更高层级的LSTM转换为整个文档或段落的表示。解码阶段与此类似,但过程是逆向的,从文档表示开始逐步解码出句子和词。这种层次化方法有助于模型捕捉文本数据的内在结构和复杂性。

词语 – 句子 - 文档 反解回;
感觉这个可以拿来试试做论文翻译


如果能处理视频就好了,这样监控就再也不用人去看了



Day 21 Self- Attention
选修部分



学完自适应 再回来看看

Sequence Labling

假如我们现在有一个需要读完全部句子才能解的问题, 那么red window 就需要变得是最大的(最长的句子);
其实这里大家有没有想过,这个玩意儿就是个卷积网络CNN,所谓的window 就是卷积核

what is self Attention?


how self-attention work



主要考虑 Dot -product

 实际操作自己也要做关联计算qk
实际操作自己也要做关联计算qk

如果b^1^ 和 v^2^ 比较接近的话,那么我们就说这a1 和a2 比较像

b1 –b4 是同时产生的
 矩阵运算的角度
矩阵运算的角度

你也可以不做softmax(Relu 也行)

(小bug是 a_head 换成 ‘)


Multi-head -self-attention



Positional Encoding


hand - crafted (s to s 的规则使得不会超过位置信息)
can learned from data

这里感觉不到数学的巧妙,只是感到了工程的流水线的简洁和高效
Applicantions




Self -attention vs CNN



弹性较大,数据较小的时候容易过拟合
提问:
- 我们知道 fc 和cnn差不多(无非是fc更宽一些,如果你把cnn当初fc做的话有可能丢失位置信息,或可能需要postion encode),那么问你为什么不把windows变得很大去卷积呢?
- 如果说像老师说的
- 无法得知最长的sequerence
- 参数量大(这里不太明白参数量大在什么地方)
Self-Attention vs RNN



- 这里和我理解的差不多,就是特征彼此离得太远有点记不住了
- RNN 无法进行并行计算

Self - Attention for Graph

 可以做智能知识图谱哎,相关性度量;this is one type of Graph Neural Network(GNN)
可以做智能知识图谱哎,相关性度量;this is one type of Graph Neural Network(GNN)
Day 22 Transformer
seqence to seqence
有什么用呢?





Encoder




how Block work
仔细讲讲Residual 的过程?
重构


Decoder - AutoRegressive





Mask



由于是文字接龙,所以无法考虑右边的 info





另一种decoder

Encoder to Decoder – Cross Attend



怀疑begin那里没有做 Norm是bug


Training


很像分类的问题


Teacher Forcing : using the ground truth as input
Tips




how to resolve that?








ResNet
最核心的思想就是 恒等映射吧


那么现在来提出几个问题:
- 为什么deeper 以后train L 会增加?
- 恒等映射会解决什么问题?能否解决梯度非常陡峭的问题?
- 你想到了什么模型有类似的问题,如何进行改进的?

assumption & answer:
- parameter 的累积影响到梯度下降法,使得梯度消失(也有可能梯度变得很大 )(类似RNN)
- 可以用来处理梯度平缓 也就是梯度消失的问题;(0.0001 和 0.9 的梯度都是0);引入恒等映射相当于不论我叠多少层,L(MOdel(x)-x) = w ^2^ (假设我这里超过两层就用恒等映射),则避免了 w^999^ 出现的 梯度消失和梯度变化陡峭的问题;
- RNN 中的梯度变化 — > LSTM 引入记忆细胞和门控开关解决(但是LSTM 相当于用上一层的输出求和来抵消w变化的程度使得当0.9^10^(1000) 和 0.1^10^(10)) 差距比本来要大一些,尽可能抵消参数指数的影响

参考论文:Deep Residual Learning for Image Recognition
隐马尔可夫模型(HMM)
好吧隐马尔可夫模型出现的次数实在有点多;今天来讲讲吧
先来四个概念:
- 可见状态链 观测结果
- 隐含状态链 产生结果的实体类型
- 转换概率 相邻实体之间转换的概率
- 输出概率 实体输出结果的概率
两个基本假设:
1) 齐次马尔科夫链假设。即任意时刻的隐藏状态只依赖于它前一个隐藏状态。
2) 观测独立性假设;实体输出结果的概率完全独立
本来说的是参考几篇文章来写,tmd好多错啊;没办法只能自己去啃书了

提问:
- R 一般在实例中指什么?
- 什么是概率求和规则?
- 如何利用概率求和规则消去R?

关于复杂度的说明
在某个条件下得到某个属于a的物体的概率。 或是说一个属于b的物体等于属于a的物体的概率加上得到属于b的物体的概率减去同时属于ab的概率。

暂时回答不了剩下的两个,先姑且理解为 不用我们HMM模型你就很难求出来就好~
HMM
一种动态贝叶斯网;我知道我知道你肯定一堆破问题(为啥动态,啥就是贝叶斯网了,别急等等我告你)


这三种概率弄到你的脑子里;
然后三个基本问题:

我个人觉得第三个问题最有意思,因为特别像我们平时说的极大似然估计


好好好 势函数的概念真尼玛抽象–> 可以简单理解为一种考虑了相邻团的依赖的团的概率分布,然后后面那个Z 就是归一化,保证了这些势函数(自己定义出来的抽象玩意儿)之间的和等于1;后面团的概念和离散数学里的一个玩意儿挺像的;多读两遍吧应该是能读懂的,小伙子加油;


好理解的;看上面

多bb一嘴,会的当我放屁;条件独立:有了某个条件A就B独立(原来独不独立不知道哈,也不关心)另外,这玩意儿读起来是真的爽啊!比那些水了吧唧的博客爽多了

令人遗憾的是这里卡死了又一次;复习了一下概率论里面的全概率公式,这里又打通了
(上面那个应该是*号 因为fine的定义就是这张关联的依赖)如果我们尝试把A’∪B’当作样本空间的一个划分的话确实会得到上面的式子;but A∪B 并非啊;(MD 我学的 好烦躁啊)


截至到条件随机场之前,理论上差不多可以自圆其说了,但是我相信还是会有很多bug 后续迭代吧……
学习方法总述:
- 极大似然估计 – 面对不熟悉的理论问题,尽可能往自己熟悉的相关domain 迁移,在一开始 的过程中忽略看似矛盾的地方,后续随着内容和理解的深入迭代,会得到更好的特征
- 反向传播 – 对于一些复杂的推理来说 ,结果往往是比较简单的,可以又果溯因,结合正向传播会更快的得到推导的理解
- 学习时候大多数时间要觉得自己是傻逼,别人是牛逼;努力去弄明白他要讲什么东西,他想告诉你的是什么,忽略他讲的一些不如意的地方,反而去理解,沉淀;有基础以后,创新的时候要自己反馈,认为自己是牛逼,别人都是傻逼;
—–参考《机器学习(周志华)》
Day 23 Self - Atention 变形
关于很多个former 的故事
痛点:
在于做出注意力矩阵之后的运算惊人

由于self - attention 一般都是在big model 的一部分,所以,一般不会对模型造成决定性的影响, 只有当model 的输入较长的时候, 例如图中: 图片处理 : 256 * 256 的输入,self-attention 就会得到一个 256 * 256 的平方的 矩阵;导致运算量巨大
methods : 使用人类的先验知识
Local Attention / Truncated Attention

有的时候我们只需要知道左右另据;仅仅知道很小的范围;
感觉和双向RNN 差不多啊……好像还不一样,因为RNN 还是比较有时间序列的
老师说这里和CNN比较像, 可并行
Stride Attention

Global Attentiion

tushi 的是第一种的 attention matrix; 通过special 间接的传递信息

做多 头

//todo 这里忘记了什么是多头的概念了,多头自注意力是怎么做的来着?
Can we only focus on Critical Parts ?

有没有办法估计一下较小的值,直接抹零?
how we do that ?
Clustering


提问:
- 为什么是计算相似的而不是计算不同的以保持模型的多样性, 久像 pca 那样
- 自注意力机制算的是不是相似程度的矩阵?
- 如果是的话, 这样做为什么就能得到sequence 的全局信息了?
这里我突然蒙圈了,这里wei’啥是 4* N * N * 4呢? 而不是反过来,换句话说, 这个矩阵的大小为啥是序列的长度,而不是向量的维度
// todo 这是因为自注意力机制的目的是计算序列中每个元素对于序列中每个其他元素的注意力得分,所以我们需要一个 N×N 的矩阵来表示这些得分。每个元素都有一个对应于其他所有元素的得分,包括自己。
md 明白了, 还是需要有一个人来给自己点拨点拨呀

特色就是新弄了一个network ;没讲的是如何从右边到左边binary 的 map
台大学生提问: 这里真的有加速吗?其实我也满想问的,奈何时间不允许啊!!!
NN 里面只会产生一个10*10 的解析度较低的matrix


这里的value 表示什么意思? 是不是输入?
//todo
注意这里为什么不也用 有代表性的 query ?
会改变我的output , 导致不能使得squence的每一个part 都有一个lable 被分出 ,例如词性标注
提问:为什么是 QKV ? 而不是KQV?
好啦 这个问题其实有点蠢了, 当你KQV 的时候 ,你的K 就变成了 Q ;Q 就变成了K ;和你做函数的代换法的时候 用 u 代表变量 x 的行为没什么两样啦
Reduce numbers of Key

做不同方式的线性组合, 其实我的想法 那么也很简单, 用pca 做一下,说不定也可以, 反正就是减少运算量嘛~

为啥这里的v 可以和 其他的维度不同?
emmm 比较简单了
- 1N * N * 3 = 1 3
- b = $\Sigma$ a‘ * V
可以看到 V 只需要×一个数字, 当然就不需要一样啦

好吧 V K ^T^ Q 其实差不多就是输出了(如果我们忽略掉, KQ 之后 的softmax ,md 我也忘了这里的作用了)
将原始计算分值整理成所有元素权重之和为1的概率分布;另一方面也可以通过softmax的内在机制更加突出重要元素的权重;
自注意力机制是注意力机制的变体,其减少了对外部信息的依赖,更擅长捕捉数据或特征的内部相关性。自注意力机制的关键点在于,Q、K、V是同一个东西,或者三者来源于同一个X,三者同源。通过X找到X里面的关键点,从而更关注X的关键信息,忽略X的不重要信息。
Change the orders –Linear Transformer
这里先假设没有softMax 的情况哈



md 推荐 线性代数 – 李宏毅了 要开始;
ps 好像赚钱买mac 啊 ……


交换后:

好家伙 改了一下乘法的次数 变了这么多;
but……


while when how we add the softMax








Lets put soft Max back ……




template == pattern
how to 

Synthesizer

重新思考 attention weight 的价值到底是怎么样的
Attention -Free?


